Token Cost Efficiency
It’s the last day of Q2 2026.
A friend in Tokyo just told me he reduced token expenditure by 5x maintaining development outcome.
If I was to pick a hot AI topic leading into Q3 2026. It would most certainly be token efficiency.
At TiviTi we also reduced spend maintaining development outcome.
That’s right;
A simple workflow efficiency improving development outcome reducing token usage by 50%.
Most engineers use frontier models to write, evaluate and test code.
All foundation level providers;
- OpenAI
- Anthropic
Currently offer a breadth of very capable models at lower cost tiers.
A typical developer might spend time like this;
- 30% development
- 30% evaluation and review
- 40% testing
For evaluation, review and testing we found that using lower tier models saved time and token usage.
Models respond much faster. Response quality is on par or very close to frontier capability.
The current, “lower tier models”, built most of the hype.
Sonnet, GPT-5, Gemini 2.5. Very capable.
Much of the market strain on frontier providers is mapping the models to more challenging use cases.
I.e. Scientific discovery etc. That’s not comparable in terms of complexity to coding tasks.
Measuring, visualizing and optimizing token expenditure will help you save money.
Optimizing model choice across evaluation, review, testing and development for your use case will do this. Lower cost tiers are your friend.
We first did this;
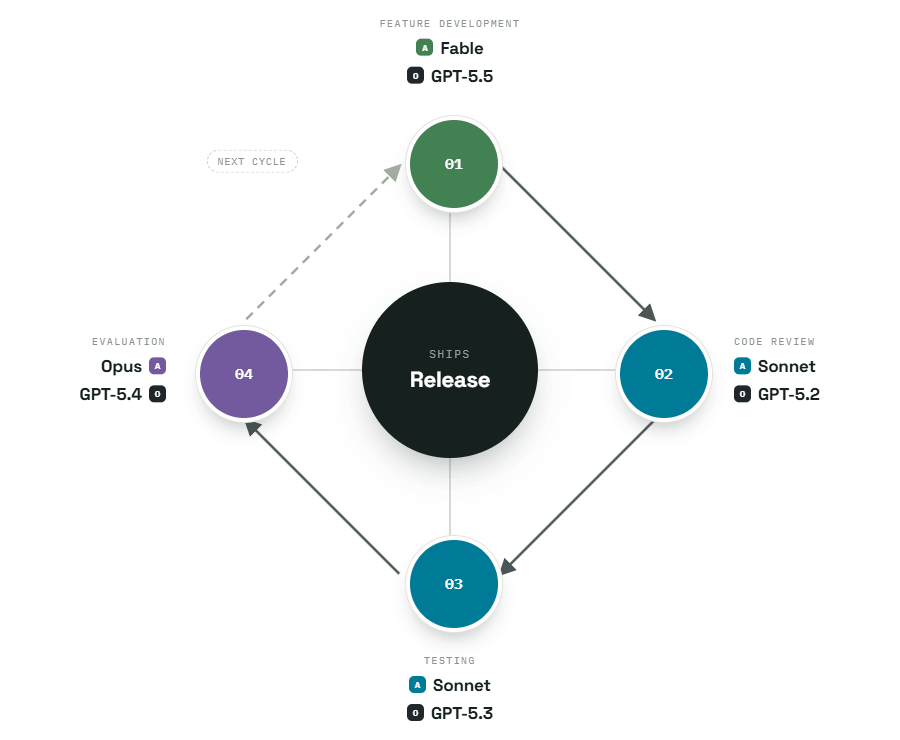
Model choice optimization saving 50% relative to “frontier only” with the same development outcome. *Fable substituted as current frontier model
This is ~70% token usage away from frontier models at 30:30:40 task allocation.
~50% cost saving relative to frontier only (Fable only).
We took this a step further. We needed to verify development outcome was maintained.
At this price point, does AI get more wrong?
How often do older frontier models make mistakes in scope?
To no surprise, prompt quality and planning matters.
When controlled, this came down to uncaught hallucination.
A human (or agent) in the loop that misses a mistake.
This happens more than you think. Not necessarily a bug, maybe its syntax quality, a comment etc.
Does a 50% savings reduction maintain development outcome?
Frontier providers actively take measures to minimize measured error release to release.
In other words, the newer models are scoped to pick up errors of older models.
Why? Because it’s easy to measure, everyone has the data… particularly in coding.
That means in theory that a newer model should be able to pick up the mistakes of older models much better than reverse.
I.e. Having Sonnet review Fables code is sub-optimal (or an engineering choice). Because Sonnet’s boundaries are smaller than Fable’s, and LLMs still arguably don’t generalize well.
Thus, we changed our cost saving approach.
Second-tier frontier model develops, and the latest frontier model reviews and evaluates.
Summary below;
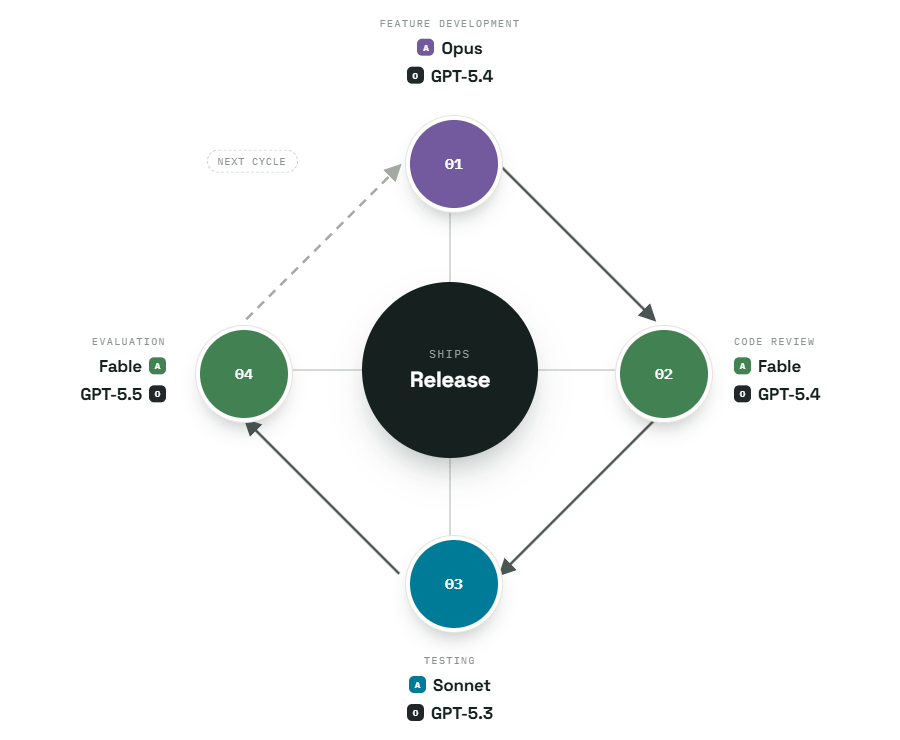
Model choice that saves 40% relative to “frontier only” with greater development outcome.
This compared at around 40% cost reduction. We found our development outcome was improved relative to previous.
What’s the upside?
Opus and Sonnet are exceptionally good at development, particularly with good planning.
If you are willing to accept a small reduction in development capacity the upside becomes a bounded review (agentic risk mitigation).
Meaning a more capable and intelligent model picks up errors across less capable models.
That’s less development risk for your organization.
It’s a tighter loop for both human-assisted and agentic development workflows.
The diagram below summarizes the workflow process efficiency;
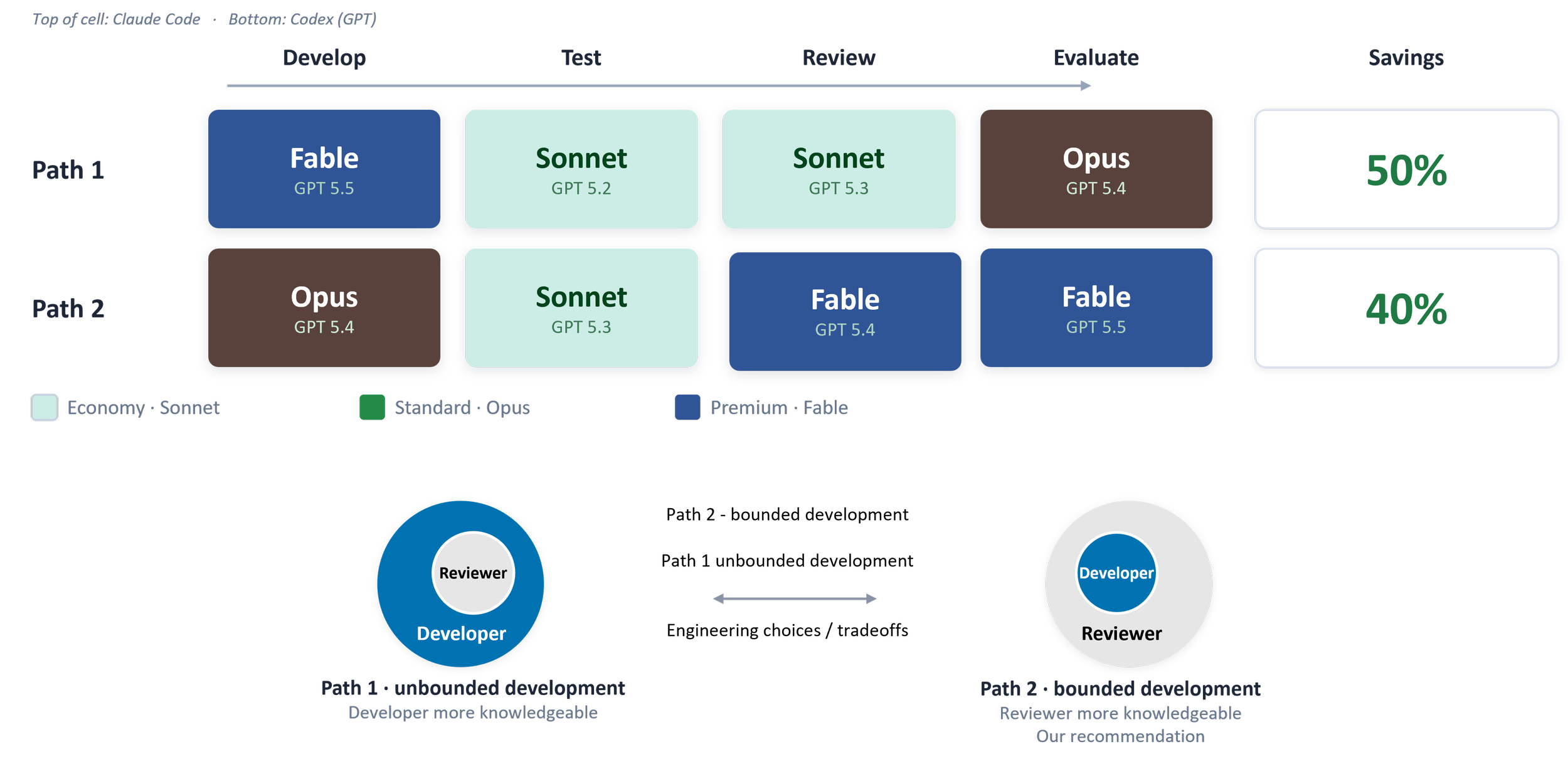
Workflow efficiency for code development tasks that can save token usage and maintaining development outcome
It is a direct applied example of our business swapping to cheaper models, for some tasks, with similar outcome.
How does this map to consumer spend over the next 6 months?
AI early adopters are coming from ~9 months embedded in AI workflows.
They understand value, relative to their work, much better than Q4 2025.
With these consumers having access to;
- Change providers (cheaper competitor)
- Swap to a cheaper model with the same provider (lower token expenditure)
- Change subscription levels and reduce enterprise seats
That’s reduced volumetric spend.
Consumers, businesses and enterprises have many options to reduce spending, maintaining or improving development outcome.
It will be interesting to see if global AI spending tapers off over Q3 or accelerates.
How does this play into the global economy?
Get in touch if you would like consultation on how to reduce, optimize or measure your AI spend!
P.S. With Sonnet 5 just released you have even more ways to reduce cost