How we developed with AI in 2025
“AI – Artificial Intelligence”, the word of 2025?
Yes, if you’re not using it, you’re probably behind.
Since 2022, my development, in some way has been AI assisted.
Over these years it has changed, for the better, and sometimes for the worse, in all cases powerful and informative.
Here is how 株式会社TiviTi used AI for development in 2025 (ignoring our super secrets…)
————————————————————————————————————————————————————
Likely no surprise to anyone, agentic coding models (Claude - Anthropic, Codex – OpenAI, etc.) significantly improve productivity.
Yes, the 10x kind.
Developer output cadence is the primary 10x metric, or code per minute.
These models help significantly with planning on many fronts, syntactical code quality, code review … and more (5).
However, to realize an effective 10x benefit, development is, still, highly proportional to code quality.
For most code-based systems, quality degrades with incremental development (extensibility over time) (1).
In current agentic models, we have noticed that incremental development tends to bring more mistakes, i.e. quality also tends to degrade over time.
More than what the average developer makes? Not sure. Offset by more optimal context driven development? Likely!
Considering this empirical observation, code extensibility we would argue is one of the most important system quality attributes when using agentic models. Ironically similar to human development.
Why?
Because the currency of these models is “text” or “char”.
Each incremental, low-quality character arguably increases the probability of incorrect, non-contextual, poor generalization.
Imagine a developer must review two files, both files do the same thing.
Code for file A is 1 line long, code for file B is 2 lines long, files are functionally equivalent.
File B clearly takes 100% more effort to review.
For LLM-driven development though, this is also 100% more reasoning effort.
An increased chance of reasoning error.
Not to mention each character increment literally costs more money and energy.
Thus, the derived development mantra for 株式会社TiviTi after 2025 is:
“Extensible quality”
As a result of this mantra and our learnings over 2025, we created a unit process (figure 1)
For any given development task, developers follow the diagram below:
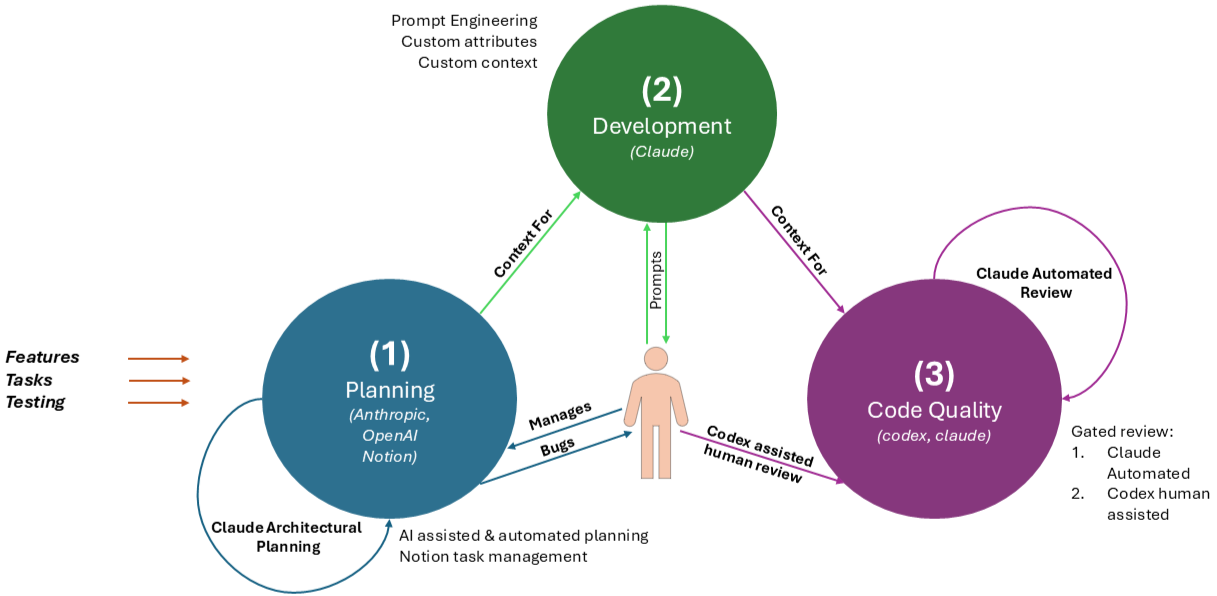
Figure 1 - Human driven AI assisted development. Typical flow for a developer executing a Notion task
So, what is each pillar?
Planning
Before AI, planning was key, we have found this is as true as ever now (3) (5).
Planning refers both to task level (1 task) and system level (multi-task development goals).
Our system level planning is AI assisted, we use AI to inform us on what tasks to create.
We ask foundation models (mostly OpenAI - ChatGPT or codex) something like:
“Given our stack and existing code, what improvements or additional features benefit our system and why?”
Maybe affording additional context like, previous tasks, market behavior, testimonials.
We enter an AI assisted conversational session.
These sessions are highly beneficial and significantly improve code outcomes and engineer capacity. These sessions often identify the most efficient development tasks given stack choices.
Notion is also key here. Notion has modern technologies that allow us to draw on database level customized context whilst dynamically planning new tasks. This is quite powerful.
Given context is so important in agentic code delivery, having the capacity to quickly and effectively draw on a prior task, when planning new tasks, as well as metrics, is likely a technical project manager’s dream.
We are still new to using Notion; however, I would guess this is going to be very powerful in the short term.
We use the Notion API and Claude to automate architectural task suggestions, store automated code review output and create general development tasks.
Moving into next year, we have many great ideas to use this flow for project management.
When a new task is created, we enter the development phase (below), where prompt engineering is key.
Development
For any given development task, we plan and engineer prompts with care.
Significant thought is given to what the models should value and the context they should be provided.
We have observed this heavily affects agentic development outcome (I cannot stress this enough) (2)(3)(4).
Directing the model to one or two key software quality attributes (i.e. performance, reliability, security) we have found has strong benefits.
Our strongest observation over the year using agentic code delivery models is to specify existing code context alongside task goals.
This means, giving the model, at first prompt, context on existing system code that it needs to execute its goals. These may be files, functions, comments or web documentation. Together with why you have included it (if it is not already mentioned in the code).
When done well, we have found that agentic model output is much more effective and efficient.
So, what is the cost of not giving context and goals?
Yes, agentic models can still get it right and sometimes hit a home run without it.
However, the probability of this occurring, we would argue, is significantly reduced when not done. Because, as implied earlier, generalization is still evolving for these models.
Without specifying context, an LLM might generalize in a contradicted way. I.e. Presume the wrong system context or quality attribute has precedence.
Every bit of missing context arguably raises the probability of a general error.
Ironically similar to how human developers operate (without proper direction humans miss the mark on tasks too).
The result of ignoring the planning phase is decreased system extensibility and code quality, which compounds over time.
After delivering the prompt, a developer also needs to manage the agentic session.
This is non-trivial.
To do this the developer must deal with accrued session bloat or accrued session context.
We have noticed (particularly when using Claude) this matters a lot (both monetarily and developmentally).
The more bloated a session becomes (tokens), we have noticed an association with lower quality output. In Claude this means using /doctor and /context to stay informed and hitting /clear at the right times (3).
You could almost approximate agentic development outcome to accrued session token similarity (words). It would be interesting to test this.
That is, the more frequent a token, specifically in bloat (i.e. “security”). It may be the greater chance of generalized error.
This means two things:
1) It is the developers’ job to continue to communicate succinctly and accurately,
2) Recursive developer prompts, following the initial engineered prompt, should not contain incremental bloat, unless necessary.
Interestingly, both caught and uncaught errors in agentic coding sessions may lower development outcome.
Because in both cases a session may become bloated further.
As a result, we try to use short, directed, efficient development sessions (ideally no longer than 30 minutes). A developer tracks agentic errors (mostly opinionated).
If errors accumulate too frequently tasks are stopped and restarted.
We have seen incredible value in restarting tasks early over attempting to reason into resolution.
In very rare occurrences we have seen a model, on mid-to-high complexity tasks, return from its development error with a better outcome.
When the latter occurred, I was astounded. A story for another day.
After a development task is completed, it enters review and quality management. Still the active developer’s responsibility.
Code Quality
The big one. Arguably the most important factor moving into agentic development.
Why?
Aforementioned, we have found bloat reduces model outcome.
Mitigating bloat in both existing code and to be developed code is key. A commit can easily be bloated by both the agentic model and/or the developer.
So how do we currently manage this?
A two-phase gated review process before development sign off.
Phase 1
Every commit, no matter the size, is reviewed by two agentic models. One is automated across a standardized review prompt. Output is fed into Notion.
Phase 2
Pseudo-agentic and human -led. The outcome of phase 1 is read and interpreted by a human expert.
The human uses a second (different) model to execute a manual AI assisted discussion with the developer.
A very human discussion about the review and the development task. Further refinements are made at this stage often manually by the developer.
Whilst the first phase is good at picking up bugs, added comments, error handling etc.
The second is the strongest at extensible code quality management.
When timed right the developer often supersedes the capacity of the agentic model itself in this phase.
When the goal is extensibility and code quality this phase brings into play “lean” thinking, cutting bloat.
Now some of you astute readers may be thinking, well then why do we need phase 1, if we do phase 2.
Phase 1 and phase 2 in conjunction should significantly cut code review times to sub 2 hours and should not sacrifice quality.
Phase 1 drives a developer’s thought and gives the developer context in a time efficient way. To determine what they should focus on in the AI assisted coding session.
Phase 1 makes phase 2 more efficient and often brings pleasant surprises.
Phase 1 and phase 2 give the developer back time, which should translate to human capital.
Overall, this does a few things:
1) Speeds up review processes, worst case same speed
2) Brings a lean mindset, driving quality + extensibility
3) Still empowers the human developer
Whilst we have many thoughts on how to improve this moving into next year, this is where it currently stands.
TL;DR: The agentic models are very powerful reviewers. Playing the models off against one another can bring some very interesting surprises.
-------------------------------------------------------------------------------------------------------------
What did we build with this process?
Over the course of three months, we used and refined this process to build a Google Maps-based stack which can securely and efficiently deliver map-based analytics and insights interactively.
It’s not perfect, this was the first time we have done this. However, it is developed in a much shorter time than historical technologies, with a much smaller team.
It’s fast, efficient, kind of fun and most of all extensible.
Meaning the cost of incremental development, we believe, is empowered by AI moving into 2026.
Below is a screenshot and short description of features we built over the development period:

Figure 2 – Interactive, geometry responsive map, leveraging dynamic backend polling to visualize geo-spatial data states
Features
· Interactive data responsive graphical timeline
· Efficient dynamic API backend data polling
· Responsive marker geometry based on dynamically polled JSON data structures
· Rendered viewport optimization
· Anonymized session-based defense in depth authentication
· Transport / Network isolation
· RAF based marker updates
· Efficient database management
And much more…
株式会社TiviTi aims to use emerging technologies to help solve emerging problems. We hope to help companies visualize their supply chain to improve the quality of food they distribute.
Thanks!
References
1) Lehman, M. M. (1996). Laws of software evolution revisited. In C. Montangero (Ed.), Software Process Technology (EWSPT 1996) (Lecture Notes in Computer Science, Vol. 1149, pp. 108–124). Springer. https://doi.org/10.1007/BFb0017737 (link.springer.com)
2) Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR 2023). OpenReview. https://openreview.net/forum?id=WE_vluYUL-X
3) Anthropic. (2025, April 18). Claude Code: Best practices for agentic coding. Engineering at Anthropic. https://www.anthropic.com/engineering/claude-code-best-practices
4) OpenAI. (2025, December 12). How we used Codex to build Sora for Android in 28 days. OpenAI. https://openai.com/index/shipping-sora-for-android-with-codex/
5) OpenAI. (n.d.). Building an AI-Native Engineering Team. OpenAI Developers (Codex Guides). https://developers.openai.com/codex/guides/build-ai-native-engineering-team/